La clasificación no supervisada es una forma de clasificación basada en píxeles y es esencialmente una clasificación automatizada por computadora. El usuario especifica el número de clases y las clases espectrales se crean únicamente en función de la información numérica de los datos.
Las ventajas de usar este método es que es bastante rápida y fácil de ejecutar. No se requiere un conocimiento previo extenso del área, pero debe poder identificar y etiquetar las clases después de la clasificación. Las clases se crean basándose en información espectral, por lo que no son tan subjetivas como la interpretación visual manual.
La desventaja es que las clases espectrales no siempre corresponden a clases informativas. El usuario también tiene que dedicar tiempo a interpretar y etiquetar las clases siguiendo la clasificación. Las propiedades espectrales de las clases también pueden cambiar con el tiempo, por lo que no siempre se puede usar la misma información de clase al pasar de una imagen a otra.
Ahora veremos un ejemplo de cómo realizar esta clasificación utilizando la herramienta de SAGA “K-means clustering for Grids”
Comenzamos cargando en QGIS las 4 bandas interesantes para estudiar la vegetación de la imagen Landsat 8 que descargaremos de la plataforma oficial. Aquí puedes ver cómo hacerlo Descarga de bandas LANDSAT 8 y su combinación en QGIS 3.
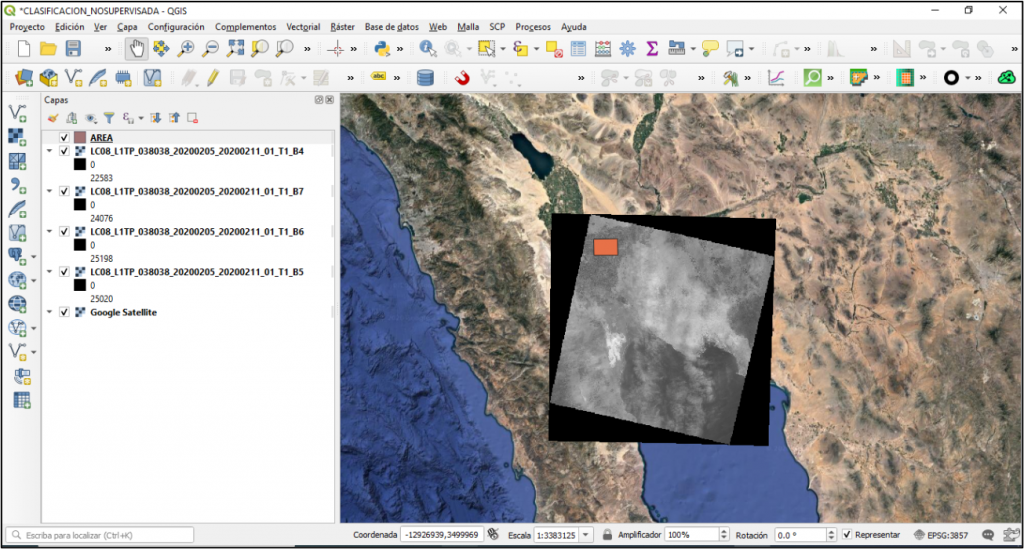
Lo siguiente que haremos será recortar la imagen que descargamos en base al área de nuestro interés.
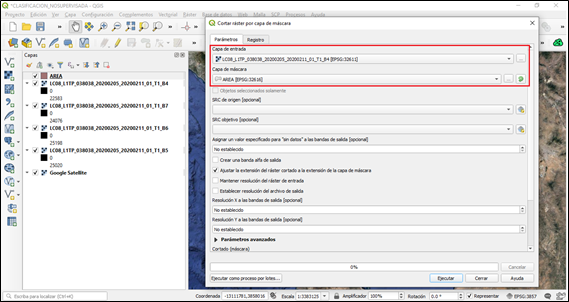
Repetimos el mismo proceso con cada una de las bandas.
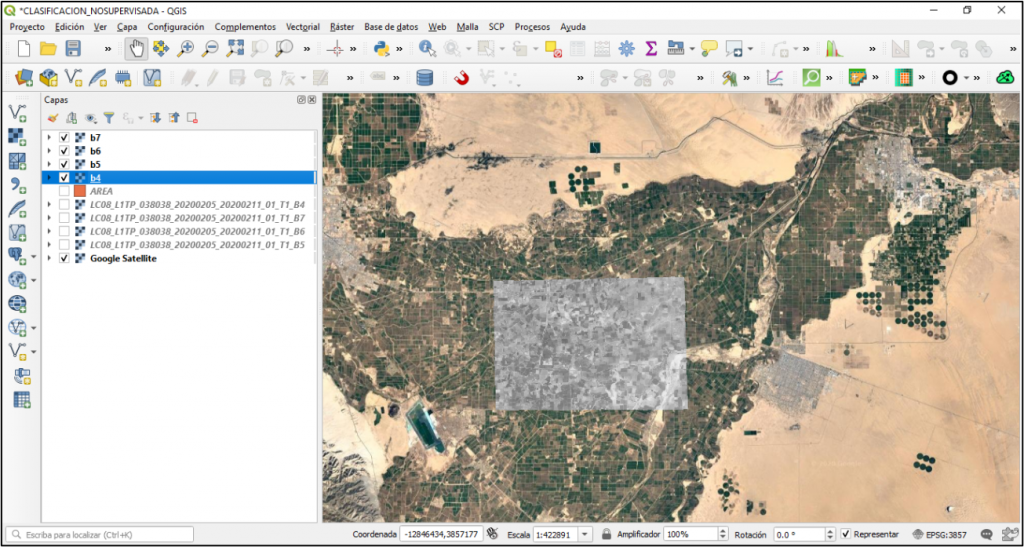
Una vez recortado la zona de interés, lo siguiente es realizar la clasificación no supervisada del área, en esta ocasión lo haremos con la herramienta de K-means clustering for Grids de SAGA.
Accedemos desde la caja de herramientas desde el menú Procesos/Caja de herramientas. Una vez ahí, seleccionamos Saga/Image analysis/K-means clustering for grids.
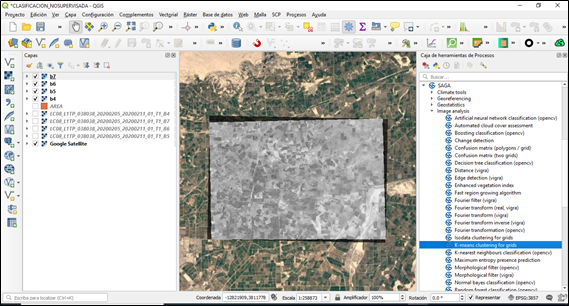
Ingresamos los datos, en “Grids” cargamos las 4 bandas de nuestra imagen satelital recortada. En “Method” seleccionamos “Iterative Minimum Distance”, con este método se busca agrupar los centroides que se distribuyen inicialmente de forma aleatoria, por lo que este método es de los más adecuados a la hora de la clasificación en vegetación. En “clusters”, seleccionamos el número de clases que queremos que se generen, para este caso elegimos 5 clases, las demás opciones las dejamos por defecto.
Cabe señalar que este método también nos permite obtener las estadísticas de los resultados.
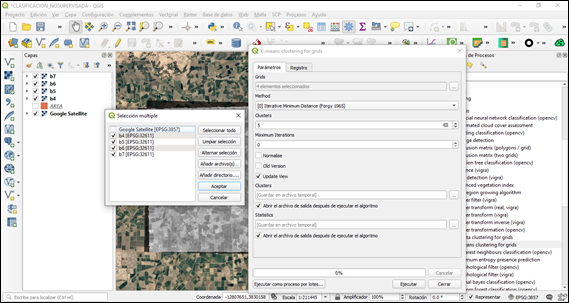
Corremos el proceso, este puede llegar a tardar dependiente de tamaño de área a procesar.
Una vez obtenido el resultado podemos modificar las opciones de visualización de simbología de los resultados y poder analizar los resultados obtenidos.
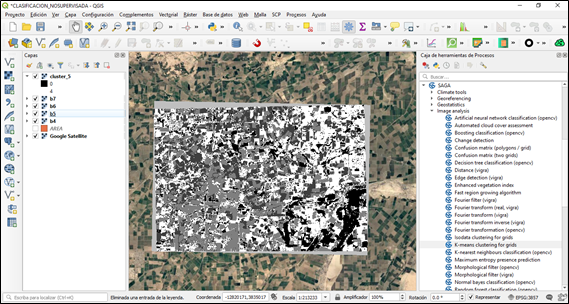
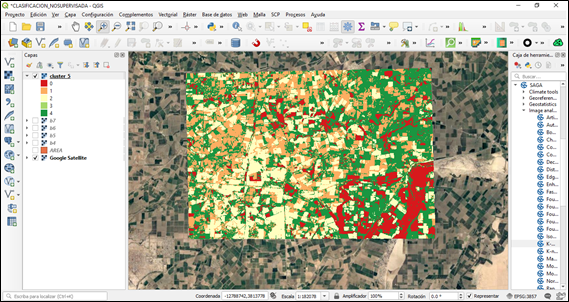
La clasificación no supervisada puede resultar de gran utilidad cuando no se disponen de datos de campo o como paso previo a una clasificación supervisada.

 (4 votos, promedio: 4,75 de 5)
(4 votos, promedio: 4,75 de 5)![]() Cargando...
Cargando...
Formación de calidad impartida por profesionales







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Deja tu comentario